
This is the first in a series of posts exploring uses of artificial intelligence/machine learning (AI/ML) for advancing democracy (for the context, see this Q&A)
Law in modern democracies has a fundamental asymmetry. Legal language is complex and technical; law decides disputes involving very large amounts of money; and so the ability to handle the law is specialized and expensive. Lawyers are both expensive and make an enormous difference to one’s odds. Institutions have been built to mitigate the damage to the law’s democratic promise —pro bono obligations, public defender offices, civil society legal organizations, and so forth. But these often have strained resources, and with every year the law grows more complex, the stakes rise, and costs grow.
As part of my work exploring how machine learning (ML) might advance democracy (instead of just threaten it), I’ve been thinking about how new applications of machine learning might address that imbalance. Doing so will involve a lot of work with text models, including generating small pieces of structured text in a specific style, with little input data. So as a mini test of concept, we’ve been working on an algorithm to write sonnets in the style of Shakespeare. More on that below.
Legal tech for public interest law
In the last five years a field has emerged called “legal tech” (an inevitably ugly term). It involves using machine learning techniques developed to handle and generate text to automate some legal tasks. For example, machine learning models may analyze large volumes of documents, looking for anomalies in the text, and therefore help sort and rank which should be read in more detail. Others may generate first drafts of complex contracts based on a limited set of inputs, again for later review. Such uses do not do away with lawyers, but try to reduce the time absorbed in routine tasks by time-limited or just very expensive associate lawyers.
Commercially, legal tech has had some successes, but has struggled to achieve the break-out success of many other tech fields. High-prestige law firms set industry standards, and those firms charge per hour, so they have no incentive to reduce the number of hours their lawyers work.
That dynamic is, though, different for public interest lawyers. They are often severely resource constrained. So too are ordinary people. One of the most promising legal tech companies, called DoNotPay, started out helping people get out of parking tickets that had been issued to them arbitrarily or against regulations. Needless to say, there is a distinct possibility that AI/ML won’t be very helpful in improving access to the rule of law. Law is high-stakes, and faddish technology that is beside the point or doesn’t work will be harmful. But recent advances provide at least some hope.
Transformer networks and transfer learning
Up until the last few years, ML techniques for generating text, from scratch or from existing documents, had limited abilities and needed huge amounts of training text for every task, even niche ones. Two advances in recent years though may have changed that.
The first has been the development of “transformer” neural networks. These have worked extremely well in tasks like translation, summarization and text generation. Unfortunately, these giant text models have inherent energy and bias problems. The most famous one, “GPT-3”, is closed under a commercial license, but many others are at least open.
The second advance has been in what’s known as “transfer learning” and “fine tuning”. That involves taking a machine learning system built with a large amount of data elsewhere, and adapting it to a new task, with a much smaller amount of data. The question now is whether fine-tuning such models can provide one tool for democratic legal tech.
What does this all have to do with Shakespeare?
The models will need to learn to output highly structured text, in a specific and unusual style, from a small number of clearly laid out documents. Another set of texts answers to that description: poetry. Shakespeare’s sonnets, for example, are highly structured, have a specific and technical style, and are easily available in a clean text format via Project Gutenberg.
If a model can learn to generate a sonnet from a few keywords, or a sentiment, or out of the blue, it is at least plausible to see extensions into paragraphs and then sections and so forth. On the other hand, if even that isn’t possible, it’s likely too early to start thinking about generating legal text.
So that has been one of the first tasks I’ve explored. One possible approach might be to use a “generative adversarial network” (GAN), the same technology used for creating deep fake images (hence an early nickname for the project, “DeepShake”).
Another approach is to use one of the giant pre-trained models and fine-tune it (using the amazing HuggingFace library). Here, I’ve run a first experiment, using the “T5” model–developed by Google to handle general text-to-text translation. Then the question becomes: what exactly is the data to feed into the fine-tuning? A fair test would be to go through all the sonnets one weekend and label each with a sentiment, and then feed in the sentiment-sonnet pairs. But I wanted a hard test, i.e., the ability to generate a poem out of nothing, with no guideposts.
From noise to Shakespeare?
So I set up the task as having the model translate “noise”, randomly generated gibberish, into a line of Shakespeare. I created a little routine to generate pairs of such “noise” and one or two or more lines pulled from the sonnets. Then I fed a few thousand, and later tens of thousands of such pairs of noise and poetry into the model. It took a bit of work to get everything in sync, but then DeepShake was trained and started generating sonnets. At first, the results were exciting. The model seemed to generate passable lines, though with a tendency to start lines with “And yet” and close them with enjambment. I sent a few of the sonnets to a friend who’s a Shakespeare scholar, and she responded that one or two were “almost interesting”.
Unfortunately, DeepShake was a plagiarist. When fed a large number of noise-poetry pairs, it seemed to generate, with suspicious frequency, the line: “And yet methinks I have astronomy”. That’s a line from Shakespeare himself (Sonnet XIV). In a way, the model learns it as the most probable line the sonnets, given the distribution of language within them. That is interesting, but unfortunately a dud for our purposes. The frequency of “And yet” to start a line has the same origin–it’s just the most likely start to a sonnet line, by a wide enough margin that it starts ~80%+ of the lines that DeepShake generates. More training, or more lines, doesn’t help: the model just learns how to plagiarize more reliably.
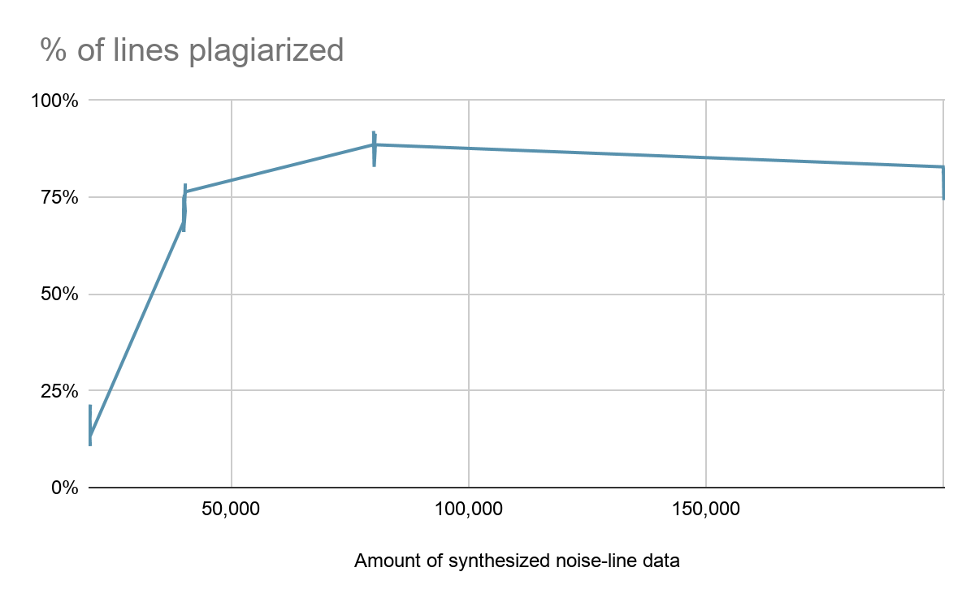
Having said that, not all is lost. Every now and then a phrase appears like, “To be a prostitute of prides”, which appears nowhere in the sonnets. There are parameters that need further exploration. And, of course, this is just one approach to using ML/AI techniques to help understand and in time transform the rule of law.

Sample DeepShake sonnet.
Future posts, as well as updates on text generation, will cover summarizing, as well as using graphs of cases and judges to understand the relative centrality of different acts, sections and parts of the judiciary (for example, to prioritize advocacy).
On the first, we’ve used the South African Constitutional Court’s tradition of issuing “media summaries” for its judgements to assemble an initial dataset, and on the second, a huge dataset from the Development Data Lab to assemble a graph of tens of millions of nodes. I and others in the team working on this will soon be writing more about those initiatives. So stay tuned! And if you’d like to explore a practical use case on the ground, let us know.
This year, MIT GOV/LAB is hosting Luke Jordan, Founder and Executive Director of the civic technology organization Grassroot, as a practitioner-in-residence. The position provides partners with resources to develop new projects and space to reflect on and share their experiences in the field, which will enable the lab to better ground its research in practice.
Photo by Jessica Pamp on Unsplash.